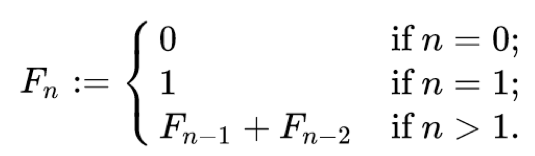nullable(DDL) : null 값의 허용여부를 설정한다. false로 설정하면 DDL 생성 시 not null 제약조건이 붙는다.
unique(DDL) : @Table의 uniqueConstraints와 같지만 한 컬럼에 간단히 유니크 제약조건을 걸 때 사용한다.
columnDefinition(DDL) : 데이터베이스 컬럼 정보를 직접 줄 수 있다.(필드의 자바 타입과 방언 정보를 사용)
ex: varchar(100) default 'EMPTY'
length(DDL) : 문자 길이 제약조건, String 타입에만 사용한다. (기본 255)
precision, scale(DDL) : BigDecimal 타입에서 사용한다.(BigInteger도 사용할 수 있다.) precision은 소수점을 포함한 전체 자릿수를 scale은 소수의 자리수다. 참고로 double, float 타입에는 적용되지 않는다. 아주 큰 숫나자 정밀한 소수를 다루어야 할 때만 사용한다.
@Enumerated
자바 enum 타입을 매핑할 때 사용
주의! ORDINAL 사용x
value
EnumType.ORDINAL : enum 순서를 데이터베이스에 저장
EnumType.STRING : enum 이름을 데이터베이스에 저장
기본값 : EnumType.ORDINAL
@Temporal (hibernate 최신 버전에는 안써도 됨.)
날짜 타입(java.util.Date, java.util.Calendar)을 매핑할 때 사용
참고 : LocalDate, LocalDateTime을 사용할 때는 생략 가능(최신 하이버네이트 지원)
value
TemporalType.DATE : 날짜, 데이터베이스 data 타입과 매핑(예 2013-10-11)
TemporalType.TIME : 시간, 데이터베이스 time 타입과 매핑(예 11:11:11)
st = new StringTokenizer(br.readLine(), " "); for (int i = 1; i <= N; i++) { partPrice[i] = Integer.parseInt(st.nextToken()); }
br.close();
for (int i = 1; i <= N; i++) { int max = 0; for (int j = 1; j <= i; j++) { max = Math.max(max, partPrice[j] + maxPricePerLength[i-j]); } maxPricePerLength[i] = max; }
classSolution{ publicintsolution(int[] citations){ int answer = 0; Integer[] num = new Integer[citations.length]; for(int i = 0; i < citations.length; i++){ num[i] = citations[i]; }
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
1 2 3
- 0ms 시점에 3ms가 소요되는 A작업 요청 - 1ms 시점에 9ms가 소요되는 B작업 요청 - 2ms 시점에 6ms가 소요되는 C작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.
한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.
1 2 3
- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms) - B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms) - C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)
이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면
1 2 3
- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms) - C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms) - B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항
jobs의 길이는 1 이상 500 이하입니다.
jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
입출력 예
jobs
Second Header
[[0, 3], [1, 9], [2, 6]]
9
입출력 예 설명
문제에 주어진 예와 같습니다.
0ms 시점에 3ms 걸리는 작업 요청이 들어옵니다.
1ms 시점에 9ms 걸리는 작업 요청이 들어옵니다.
2ms 시점에 6ms 걸리는 작업 요청이 들어옵니다.
문제인식
‘하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.’ => 시작은 작업 요청 시점이 0인 작업부터, 바로 우선순위 큐로 정렬하면, 이 규칙에 어긋난다.
평균 처리시간을 줄이기 위해선, 작업 요청 시점 순으로 처리하는 것보다, 작업 처리시간의 적은 것부터 처리하는것이 더 효율적이다.
해결방향
문제인식 1번 부분을 충족하기 위해, 우선 주어진 배열을 ‘작업요청시점’의 오름차순으로 정렬한다.
문제인식 2번 부분을 충족하기 위한, 우선순위 큐의 인스턴스를 생성하고, ‘작업처리시간’의 오름차순의 정렬기준을 준다.
문제를 해결하기 위해, 반복문을 선언하는데, 종료 기준을 주어진 배열의 맨끝 인덱스까지, 혹은 큐가 비어있지 않을 때까지로 정한다.
3번의 반복문 안에 큐에 디스크 작업을 넣는 반복문을 선언하는데, 종료 기준을 ‘작업요청 시점’이하 그리고, 인덱스 번호가 배열의 길이미만 일때 까지로 정한다.
3번 반복문이 도는 동안, 4번 반복문을 통해 큐에 jobs 데이터가 삽입된다.
만약 큐가 비어있다면, ‘작업 시작점’에 가장 최근 ,jobs 데이터의 ‘작업요청 시점’을 넣는다.
큐가 비어있지 않다면, 큐의 데이터를 꺼낸다. 작업 처리시간은 이전작업 완료 시점 - 작업이 요청되는 시점 + 작업의 처리시간 로 이 공식대로 총 작업 처리시간을 구한다.
모든 디스크 작업의 처리시간 합계를 구하고 평균을 구한 뒤, 그 정답을 리턴한다.
주의사항
대기시간 역시 작업 처리시간에 포함해야 한다. 즉, 7번의 작업 처리시간 공식은 대기사간 + 작업처리시간이다.
매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Leo는 스코빌 지수가 가장 낮은 두 개의 음식을 아래와 같이 특별한 방법으로 섞어 새로운 음식을 만듭니다.
1
섞은 음식의 스코빌 지수 = 가장 맵지 않은 음식의 스코빌 지수 + (두 번째로 맵지 않은 음식의 스코빌 지수 * 2)
Leo는 모든 음식의 스코빌 지수가 K 이상이 될 때까지 반복하여 섞습니다. Leo가 가진 음식의 스코빌 지수를 담은 배열 scoville과 원하는 스코빌 지수 K가 주어질 때, 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 섞어야 하는 최소 횟수를 return 하도록 solution 함수를 작성해주세요.
제한 사항
scoville의 길이는 2 이상 1,000,000 이하입니다.
K는 0 이상 1,000,000,000 이하입니다.
scoville의 원소는 각각 0 이상 1,000,000 이하입니다.
모든 음식의 스코빌 지수를 K 이상으로 만들 수 없는 경우에는 -1을 return 합니다.
입출력 예
scoville
K
return
[1, 2, 3, 9, 10, 12]
7
2
입출력 예 설명
스코빌 지수가 1인 음식과 2인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다. 새로운 음식의 스코빌 지수 = 1 + (2 * 2) = 5 가진 음식의 스코빌 지수 = [5, 3, 9, 10, 12]
스코빌 지수가 3인 음식과 5인 음식을 섞으면 음식의 스코빌 지수가 아래와 같이 됩니다. 새로운 음식의 스코빌 지수 = 3 + (5 * 2) = 13 가진 음식의 스코빌 지수 = [13, 9, 10, 12]
모든 음식의 스코빌 지수가 7 이상이 되었고 이때 섞은 횟수는 2회입니다.
문제인식
스코빌 공식에 의하면, 가장 맵지 않은 음식과 그 다음으로 맵지 않은 음식을 순차적으로 꺼낼 수 있는 자료구조가 필요하다.
모든 음식이 스코빌 지수를 k 이상으로 만들어야한다. 뒤집어 생각해보면, 하나라도 스코빌 지수가 k 미만이면, 문제조건에 맞지 않는다.
해결방향
우선순위 큐를 이용하여, 모든 음식의 스코빌 지수를 오름차순으로 정렬한다.
스코빌 지수 공식에 따라, 두 개씩 뽑아야 하므로, 반복문을 선언할때, 반복조건을 큐의 데이터 갯수를 2개 까지로 제한한다.
문제인식 2번에 따라, 하나라도, k 미만의 음식이 있으면, 실격이므로, 우선순위의 큐의 최소값(head에 해당하는 데이터)이 k 미만 역시 반복조건에 AND로 추가한다.
반복문의 반복 횟수마다 섞은 횟수를 한개 씩 늘려준다.
모든 음식이 K 지수 이상이라면, head 데이터 역시 K 지수 이상으로, 반복문이 끝날 것이고, 그 반복문의 횟수를 리턴하면, 그것이 정답이 될 것이다.
만약 모든 음식을 섞었다면, 큐에 남은 데이터는 최종적으로 하나가 남을 것이다. 그 하나의 데이터가 K 지수보다 낮으면, 모든 음식이 K 지수 미만이므로 이 경우에는 -1을 리턴한다.
수많은 마라톤 선수들이 마라톤에 참여하였습니다. 단 한 명의 선수를 제외하고는 모든 선수가 마라톤을 완주하였습니다.
마라톤에 참여한 선수들의 이름이 담긴 배열 participant와 완주한 선수들의 이름이 담긴 배열 completion이 주어질 때, 완주하지 못한 선수의 이름을 return 하도록 solution 함수를 작성해주세요.
제한사항
마라톤 경기에 참여한 선수의 수는 1명 이상 100,000명 이하입니다.
completion의 길이는 participant의 길이보다 1 작습니다.
참가자의 이름은 1개 이상 20개 이하의 알파벳 소문자로 이루어져 있습니다.
참가자 중에는 동명이인이 있을 수 있습니다.
해결방향
문제 인식
‘참가자의 이름은 1개 이상 20개 이하의 알파벳 소문자로 이루어져 있습니다.’ : 대소문자 구문x
참가자 중에는 동명이인이 있을 수 있다. : 단순히 ‘이름’을 기준으로 진행하면, 중복 삭제가 될 수 있다.
‘completion의 길이는 participant의 길이보다 1 작습니다.’ : 완주하지 못한 선수는 무조건 1명이다.
문제 해결
같은 이름의 인덱스도 구분해야하기 때문에, HashMap으로 key-value에 해당하는 재너릭 변수명을 각각 ‘이름’, ‘중복횟수’로 지정하고 인스턴스를 초기화 한다.
‘참가자 배열’을 향상된 for문을 돌려 해쉬맵에 “이름”, 1로 put 하되, 같은 이름의 인덱스로 put을 하게 될때마다, 기존 ‘중복횟수’에서 1을 더한다.
‘경쟁자 배열’ 향상된 for문을 돌려 동일하게 해쉬맵에 적용하되, 이미 적용된 해쉬맵이 검색될 때마다. 기존 중복횟수에서 -1을 한다.
해쉬맵 인스턴스가 두개의 for문을 거치면, 결과적으로 0 혹은 1의 값을 가진 키셋이 형성된다. 해당 해쉬맵에 Iterator와 Entry를 이용해, 해쉬 테이블을 전체적으로 검색하고 그중에서 중복횟수 ‘값’이 1을 가진 키가 검색된다면, 그 키 값을 리턴하고, 프로그램을 끝낸다.
주의사항
다른 사람의 풀이를 보면, 간혹 해쉬앱을 바로 for문에 적용하여, 검색하는 풀이를 볼 수 있는데, 코드의 길이와 가독성을 보면 언듯 더 편리해보이지만, EntrySet의 getValue()가 HashMap의 get() 보다 사용하는 함수의 갯수가 더 적고, 실행 속도도 빠르기 때문에, 해쉬에서 값이나 키를 출력할 때는 EntrySet을 사용하는 것이 결과적으로는 더 효율적이다.